Multi-Agent GTM: From 20 AI Agents to $1.5M Pipeline
How orchestrated agent systems are replacing the traditional GTM stack
There is a phase change happening in how revenue teams use AI, and most people are still talking about the wrong part of it.
The popular version of the story goes like this: AI writes your cold emails now. Maybe it personalizes them. Maybe it scores your leads. You plug ChatGPT into your workflow somewhere, save a few hours a week, and call it transformation. That version was true eighteen months ago. It described the prompt engineering era, where the unit of value was a single AI completing a single task, and the human did everything else.
What’s actually happening in the teams generating real pipeline right now is something structurally different. They’re not using one AI tool. They’re running 7, 12, sometimes 20+ specialized agents that operate as an interconnected system. Each agent has a defined role, defined inputs, defined outputs. They hand off to each other. They feed each other context. And a small number of humans sit at the control layer, orchestrating the whole thing rather than executing individual tasks.
This is the shift from AI-assisted GTM to AI-native GTM. And the gap between teams that understand this distinction and teams that don’t is widening fast.
The progression nobody planned for

progression nobody planned for reframed as system design.
The evolution has been remarkably consistent across the teams we track. It follows three distinct phases, each with its own operational model and ceiling.
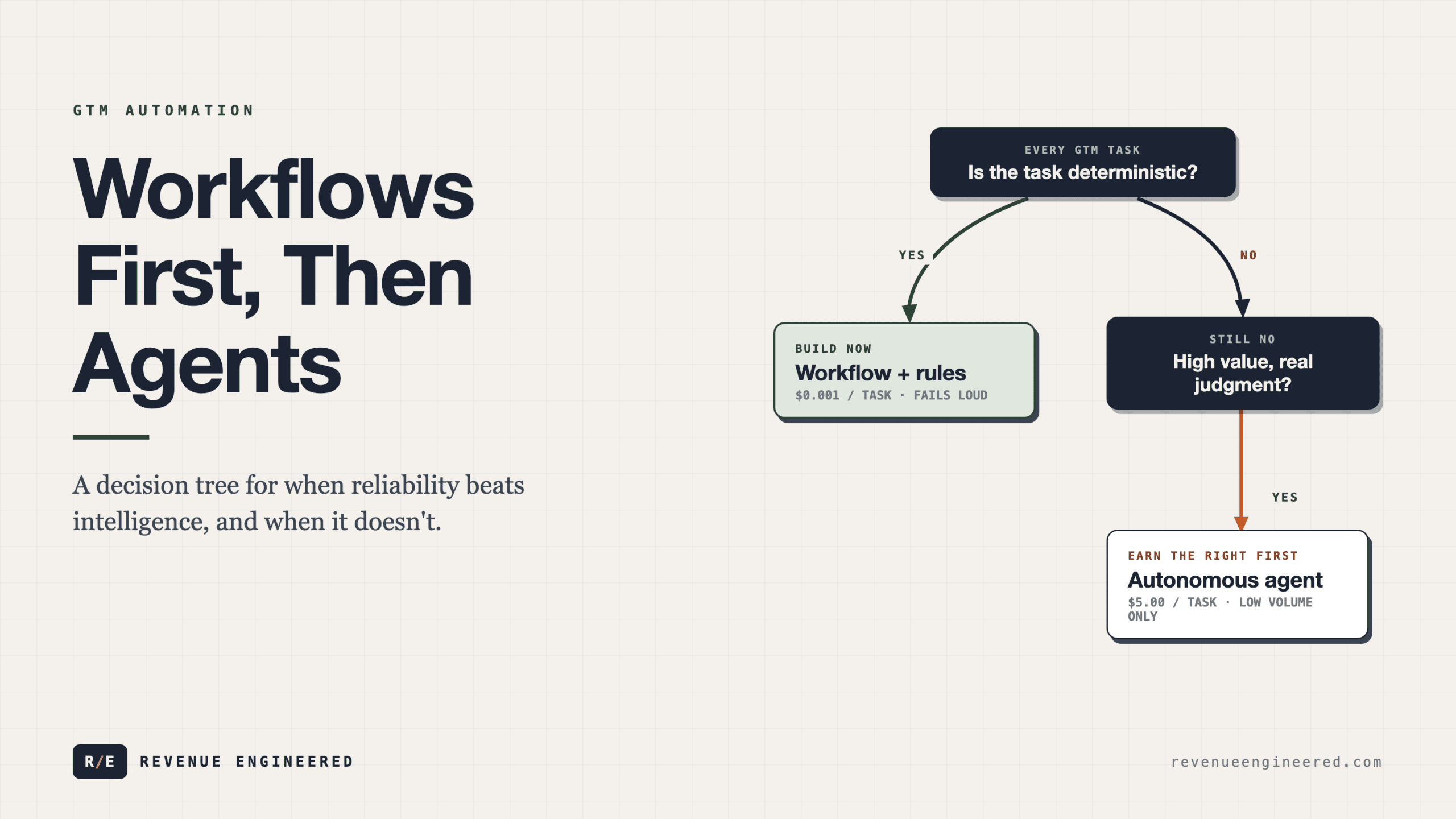
Phase one was prompt engineering. Teams discovered they could use LLMs to draft emails, summarize calls, generate research briefs. The human remained the execution layer. AI was the assistant. This worked, but it hit a ceiling quickly: you still needed one human per workflow, and the AI had no memory between tasks. Every interaction started from zero.
Phase two was single-agent automation. Teams built dedicated agents for specific functions. A research agent that enriches leads. A writing agent that drafts sequences. A scoring agent that qualifies inbound. Each one ran semi-autonomously. The ceiling here was different: you had powerful individual tools, but they didn’t talk to each other. The research agent didn’t know what the writing agent was doing. The scoring agent couldn’t access the research agent’s output. The human became the integration layer, manually shuttling context between disconnected systems.
Phase three is where things get interesting. Multi-agent orchestration means the agents themselves form a system. Agent A’s output becomes Agent B’s input. Agent C monitors Agent B’s results and adjusts Agent A’s parameters. The human moves from execution to oversight. And this is where the pipeline numbers start looking different from anything the previous phases could produce.
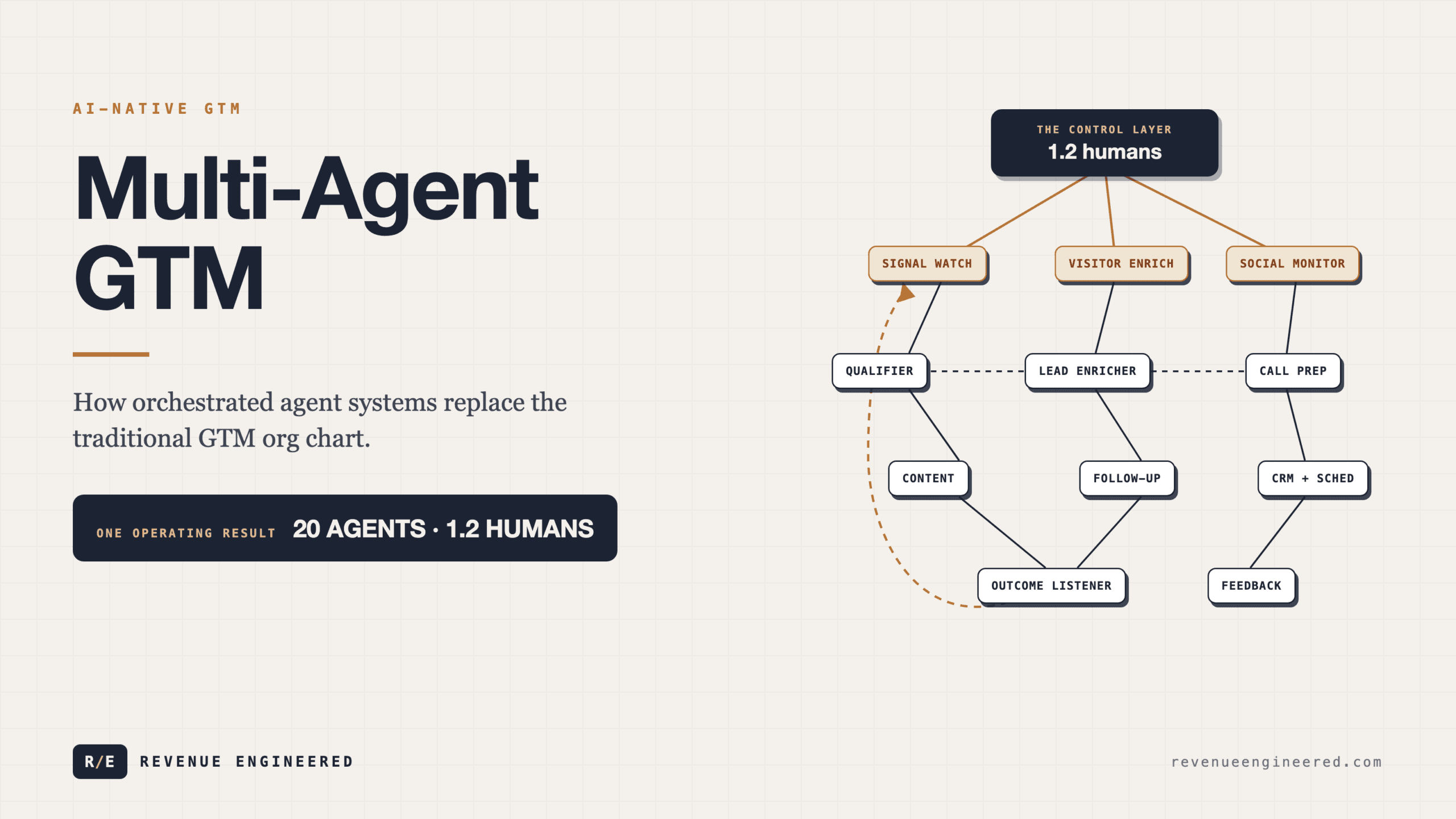
We’re seeing solo founders generate $300K in monthly pipeline with seven coordinated agents. Teams of three running operations that previously required 15 to 20 people. One well-documented case: a company running 20 agents managed by 1.2 humans, replacing what was formerly a 10-person SDR and AE team. These are not theoretical projections. These are operating results from Q4 2025 and Q1 2026.
Anatomy of a multi-agent GTM system
The architecture that’s working follows a pattern. Not identical across every team, but structurally similar enough to describe. Think of it as a pipeline of agents rather than a pipeline of leads.
At the top sits the intelligence layer. These agents handle research, monitoring, and signal detection. One agent watches LinkedIn engagement patterns across thousands of interactions, flagging people who show consistent interest based on role, company fit, and engagement quality. Another scans website visitors who didn’t convert, enriches them, and identifies the hottest prospects. A third monitors 10,000+ social reactions per month and routes warm leads the human would never have noticed manually.
Below that is the enrichment and qualification layer. Connection requests get evaluated for fit. Inbound leads get enriched with company data, recent news, competitive positioning, and stakeholder details. The output is a qualified, context-rich prospect record that didn’t require a single manual lookup.
Then comes the preparation layer. Before every sales conversation, an agent builds a research brief with potential pain points, buying triggers, and personalized opening questions. When you’re running 70 demos a week, there is no human process that keeps pace with that volume at that quality. The agent does it for every single call.
The execution layer handles content generation, sequencing, and follow-up. One agent turns raw thoughts into content that generates impressions. Another drafts follow-up emails based on call summaries and your specific sales framework. A third handles scheduling, CRM updates, and task creation.
At the bottom is the feedback layer, which is what separates this from simple automation. Agents that listen to call outcomes, track conversion patterns, and feed that data back upstream so the intelligence layer gets smarter over time.
The key insight is that none of these agents are impressive in isolation. A research agent is just a research agent. But when seven of them feed each other in sequence, the system produces something no individual tool could: a compounding intelligence network where each agent’s output makes the next agent more effective.
The coordination problem is the real problem
Here is where most teams fail. Building individual agents is straightforward. Getting them to work together without producing chaos is a genuine engineering challenge.
The failure mode looks like this: you build ten agents, each one optimized for its own task, and you connect them. Within a week, context drift has corrupted your outputs. One agent has a slightly off ICP definition. It feeds that definition into the agent classifying call transcripts. Now every transcript is tainted. Another agent analyzes those transcripts to extract pain points. The errors compound. And because AI is confidently wrong (it never tells you the data is bad), you don’t notice until pipeline quality degrades and you can’t figure out why.
This is the aviation problem applied to AI systems. One degree off in your heading, and after an hour you’re sixty miles from your target. In a multi-agent system, small errors at the top compound into dangerous divergence at the bottom. The more agents in the chain, the more severe the drift.
The practitioners solving this problem are converging on a few patterns.
The most important is what some call a Context Operating System. Rather than letting each agent maintain its own understanding of your ICP, your positioning, your sales framework, and your competitive positioning, you build a centralized knowledge base that every agent draws from. One source of truth for context, versioned and maintained like code. When your ICP shifts, you update it once, and every agent in the chain adjusts. Without this, you’re playing telephone across twenty nodes, and the message at the end bears no resemblance to what you started with.
Closely related is visibility architecture. The core tradeoff in multi-agent systems isn’t reliability (you can build in error handling and rollbacks for that). It’s visibility. When you can’t see what each agent is doing and why, you lose the ability to diagnose problems. Teams running these systems on Git, committing agent outputs and decisions as version-controlled artifacts, can roll back to any point and trace exactly where things went wrong. Teams running them through opaque SaaS platforms can’t, and they spend more time debugging than producing.
Then there are structured handoff protocols. Every agent-to-agent handoff needs defined schemas: what data gets passed, in what format, what validation happens at the boundary. Without this, agents make assumptions about inputs. With it, you catch malformed data before it propagates downstream.
The human role changes, it doesn’t disappear

human role changes, it doesn’t disappear as a maturity path.
The question everyone asks is what happens to the humans. The answer is more interesting than “they get replaced.”
In a multi-agent GTM system, the human role shifts from execution to three specific functions.
First, taste and judgment. AI agents can generate content at scale, but they can’t tell you whether that content sounds like you. They can qualify leads against criteria, but they can’t feel whether a prospect is genuinely excited or just being polite on a call. The founder generating $1.5M monthly pipeline isn’t delegating his strategic thinking to agents. He’s delegating everything except his strategic thinking. The agents amplify his strengths and cover his blind spots. His LinkedIn storytelling ability is the irreplaceable input. The agents are the amplifier.
Second, system design. Someone has to architect the agent network, decide which agents exist, define the handoff protocols, set the quality thresholds, and adjust the system when results drift. This is a new kind of GTM role, closer to systems engineering than traditional marketing or sales. The best description I’ve heard: “Remove every layer of abstraction except the context, the agent, and the user.”
Third, exception handling. The agents handle the 90% case. The human handles the 10% that falls outside the system’s parameters. A prospect with an unusual buying process. A competitive situation the agents haven’t seen before. A deal that requires creative structuring. The human’s value increases precisely because they’re only deployed on the hardest problems, not worn down by repetitive tasks.
This maps to a broader truth about where AI-native organizations are heading. The target is $10M ARR per employee. Not because employees don’t matter, but because the agents handle the volume while humans handle the complexity. The companies hitting these numbers aren’t running larger teams. They’re running better-orchestrated agent systems with fewer, more skilled humans at the controls.
The economics are already decisive
The financial case for multi-agent GTM is not marginal. It’s structural.
A traditional outbound team running 10 SDRs costs roughly $800K to $1.2M per year in fully loaded compensation. Add management overhead, tools, and training, and you’re above $1.5M. That team, well-run, might generate $3M to $5M in pipeline annually.
A multi-agent system with one to three humans operating 15 to 20 agents costs a fraction of that. The agent infrastructure (API costs, tooling, orchestration platforms) runs $2K to $8K per month depending on volume. The humans cost what they cost, but you need fewer of them, and you need them to be better. Total investment: roughly $200K to $400K per year for comparable or greater pipeline output.
The teams reporting results are seeing numbers like $1.5M in monthly pipeline from a solo operator. Or 70 fully-prepared demos per week without a single human researcher. Or 3,000 connection requests evaluated and acted on per month, with qualification accuracy that exceeds what a junior SDR delivers.
But the real economic advantage isn’t cost savings. It’s speed. A human team takes weeks to shift targeting, test new messaging, or respond to a market change. A multi-agent system can be reconfigured in hours. The ICP update propagates through every agent instantly. New messaging deploys across all touchpoints simultaneously. This tempo advantage compounds over time, and it’s essentially impossible to match with human-only teams.
Where this breaks and what to watch

Where this breaks and what to watch translated into operating choices.
This isn’t a clean story with no downsides. Multi-agent GTM systems fail in predictable ways that are worth naming.
They fail when context quality is poor. If the underlying knowledge base is disorganized, if your ICP definition is vague, if your sales framework is inconsistent, the agents amplify the mess. Garbage in, garbage out, but at twenty times the speed and with far more confidence. One practitioner put it well: you need an “unreasonable level of clarity” to properly wield the leverage of multi-agent systems. Ambiguity that a human team would muddle through becomes a systemic failure when agents propagate it.
They fail when the orchestration layer is underinvested. Teams that build agents but skip the handoff protocols, the monitoring, the feedback loops end up with what one operator described as “ten agents with no shared memory that contradict each other.” The agents individually work fine. The system doesn’t.
They fail when humans abdicate judgment too early. The teams getting the best results are the ones where the human operator has deep domain expertise and uses the agents to extend their reach, not replace their thinking. When operators trust agent outputs without verification, the system produces confident, well-formatted, completely wrong pipeline.
And they fail when teams try to build everything at once. The successful deployments we’ve seen started with two or three agents in a tight loop, proved the architecture worked, then expanded incrementally. The ones that tried to deploy fifteen agents simultaneously spent months debugging integration issues.
What the next twelve months look like
The multi-agent GTM architecture is moving from early adopter to early majority faster than most analysts predicted. Three dynamics are accelerating this.
Model costs continue to fall. The API costs that made a 20-agent system expensive in 2024 are a rounding error in 2026. This removes the last economic objection.
The tooling is maturing. Orchestration platforms, context management systems, and agent-to-agent communication protocols are becoming standardized. You no longer need a full engineering team to build a multi-agent system. A technically competent GTM operator with Claude Code or similar tools can architect one in days.
And the results gap is becoming undeniable. When one founder with seven agents outperforms a 15-person team, the pressure on every competitor in that market becomes existential. You can ignore multi-agent GTM exactly as long as your competitors do. The moment one of them figures it out, your cost structure becomes unsustainable.
The teams that will win this transition share a few characteristics. They invest in context architecture before they invest in agents. They treat visibility as a first-class design constraint, not an afterthought. They hire humans for judgment and system design, not for tasks that agents handle better. And they start small, prove the loop works, and expand from there.
Multi-agent GTM is not a future state. It is the current operating model of the teams generating the most pipeline per dollar and per human hour in B2B. The architecture is knowable. The economics are favorable. The only question is how long your organization takes to make the transition, and how much ground you lose to competitors who made it first.
Enjoying this essay?
Written by

Elom
GTM, growth, and revenue systems operator with 12 years across Fortune 500s, fintech, and B2B startups. Building at the intersection of AI, data, demand, and revenue.
Get the next deep-dive in your inbox
Essays on demand creation, GTM, growth engineering, and revenue systems. Free.