AI Agents Are Replacing Your Tool Stack (Whether You’re Ready or Not)
Context engineering, multi-agent architectures, and why the biggest shift in GTM isn’t a new tool
The most expensive software in your revenue stack is the one whose primary value proposition is a user interface that an AI agent no longer needs, not the one with the highest contract value.
We are watching a structural shift in how go-to-market operations get built and run. Not the incremental “AI-powered features” that every SaaS vendor bolted onto their product page in 2024. Something different. Agents that operate across tools, compose APIs without human input, and execute multi-step revenue workflows that used to require a human clicking through six different dashboards. The implication is not that your tools get smarter. The implication is that many of your tools become unnecessary.
This is uncomfortable for anyone who spent the last five years assembling a carefully integrated GTM stack. The CRM, the sequencing tool, the enrichment provider, the intent data platform, the attribution layer, the reporting dashboard. Each solved a real problem. Each came with a contract, an onboarding, a Slack channel, and a champion internally who understood how it worked. What is happening now is that agents can reach directly into the APIs these tools expose and do the work without ever touching the interface. The UI was the product. The API was the afterthought. That hierarchy is inverting.
But we should be honest about where we actually are. The gap between what gets demonstrated on social media and what runs reliably in production revenue operations is enormous. On one end, teams are running multi-agent workflows that handle prospecting, enrichment, sequencing, and reporting with minimal human oversight. On the other end, organizations are spending seven figures on “AI transformation” initiatives that twelve people actually use, then publishing case studies about productivity gains they calculated by multiplying headcount by a number they invented. The adoption chasm is real. The question is which side of it you are building on.
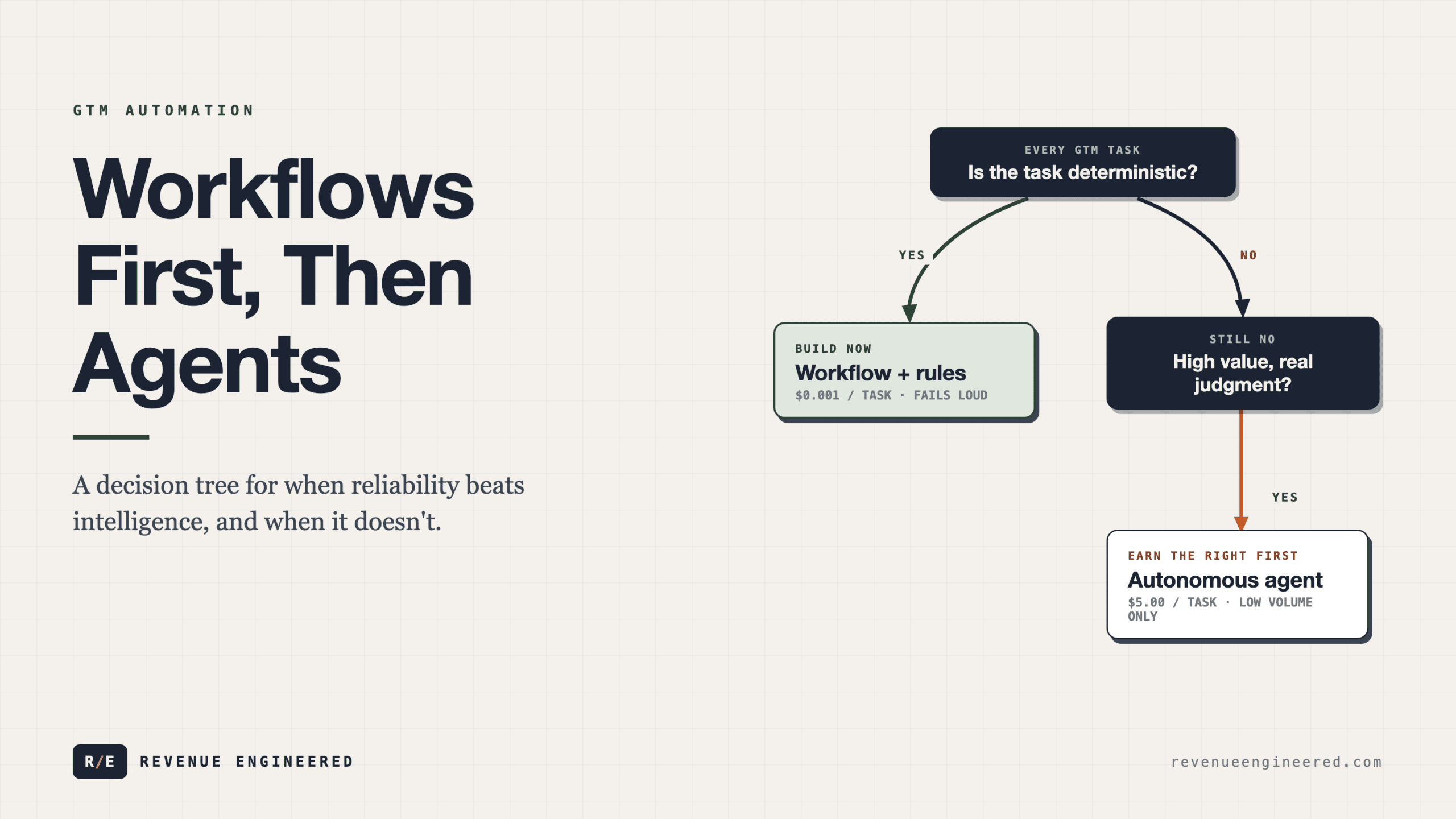
The layered autonomy model applies to GTM, not just code

Do not skip autonomy layers.
The most useful framework for understanding agent adoption in revenue operations comes from observing how practitioners actually work with these systems, not how vendors market them.
In practice, agent-assisted GTM operates across distinct layers of autonomy, and the mistake most teams make is treating the entire spectrum as a single capability. “We use AI for sales” is about as precise as “we use electricity for manufacturing.” The useful question is which layer you are operating at, for which workflow, with what verification.
The first layer is augmentation. This is where the vast majority of current adoption lives. An agent drafts an email sequence. A model scores leads based on signals you define. A copilot suggests next steps during a live call. The human makes every decision. The agent reduces the mechanical work. This layer is genuinely useful and mostly safe. It is also where most organizations stop, because it feels familiar. It looks like the tools they already use, just faster.
The second layer is orchestration. Here, the agent does not just assist a single task. It coordinates across multiple tools and data sources to execute a workflow. Pull firmographic data from one API, enrich contacts from another, check intent signals from a third, score the result, slot it into the right sequence, and personalize the first touch. A human designed the workflow. A human set the criteria. But the agent runs the entire pipeline without intervention. This is where the real leverage starts. It is also where most implementations fail, because the orchestration layer demands something that augmentation does not: reliable context management across every step in the chain.
The third layer is autonomous operation. The agent identifies opportunities, decides on an approach, executes the outreach or campaign, measures results, and adjusts its own behavior based on what it observes. Almost nobody is here in production for revenue-essential workflows. The teams that claim to be are usually at layer two with a generous definition of autonomy. Getting to layer three requires closed validation loops at every stage, and building those loops is harder than building the agents themselves.
The decision rule is straightforward. Start at layer one. Move up only when you have the verification infrastructure to support it. If your agents are producing outputs that nobody reviews before they reach a prospect or a customer, you have skipped layers. You will pay for that in ways that do not show up in your dashboard until the damage is done.
Context engineering is the actual moat

The context window is the operating system.
There is a phrase that has been circulating in technical communities that deserves wider attention in GTM: the shift from prompt engineering to context engineering. The difference matters more than it sounds.
Prompt engineering is about crafting a clever instruction. “Write a cold email for a VP of Marketing at a mid-market SaaS company.” You can optimize the phrasing, add constraints, include examples. This is the level where most GTM teams operate with AI tools today. It works well enough for simple generation tasks. It fails completely for anything that requires sustained, multi-step execution.
Context engineering is about managing the entire information environment the agent operates in. What data does it have access to? What does it know about this specific prospect, their company, their recent behavior, their industry? What are the rules governing how it can act? What prior interactions has it already seen? What does it know about your product, your positioning, your competitive differentiation? The context window is the accumulated state of everything the agent needs to make good decisions, not just the prompt.
In revenue operations, context engineering looks like this: a system-level instruction set that encodes your ICP definition, your messaging framework, your compliance requirements, your brand voice, your disqualification criteria. A session context that includes the specific account’s firmographic data, engagement history, and any prior touches. A task specification that defines what this particular outreach should accomplish and what signals should trigger escalation to a human.
The teams building durable competitive advantage with AI agents are the ones with the best context architectures, not the best prompts. Their system instructions are hundreds of lines long. Their agent configurations encode institutional knowledge that took years to develop. Their data pipelines feed real-time signals into agent context windows before every execution. This is hard to copy because it is specific to the business, built over time, and invisible from the outside.
A mediocre prompt inside a well-engineered context window will produce better outreach, better qualification, and better pipeline than a brilliant prompt inside a context window that lacks company-specific knowledge. Every hour invested in context architecture compounds across every agent interaction. Every hour invested in prompt tweaking produces a marginally better email that one time.
Multi-agent architectures for revenue
The pattern emerging in the most advanced GTM implementations is specialized agents with bounded responsibilities, coordinating through defined handoff protocols, not a single agent doing everything. This mirrors how effective human teams work, and for good reason.
A prospecting agent that monitors intent signals, firmographic changes, and trigger events. An enrichment agent that compiles contact data, validates email deliverability, and builds account profiles. A sequencing agent that selects the right campaign, personalizes each touch, and manages timing and cadence. An analysis agent that measures response rates, identifies what messaging is working, and feeds those patterns back into the system.
Each agent has its own context, its own tools, its own validation loop. The enrichment agent does not need to know your messaging framework. The sequencing agent does not need to know the details of your enrichment waterfall. Clear boundaries prevent the unpredictable behavior that emerges when a single agent tries to handle everything. When agents start “collaborating” without well-defined interfaces, the output becomes unreliable in ways that are hard to diagnose.
The coordination layer between agents is where most of the engineering work lives. How does the prospecting agent hand off a qualified account to the enrichment agent? What happens when enrichment fails to find a valid email? How does the sequencing agent know to pause a campaign when the analysis agent detects declining response rates? These handoff protocols are the actual intellectual property of the system. The individual agents are commodity components. The architecture connecting them is what makes the system work or fail.
This is also why the “buy an AI SDR” category is mostly theater right now. A single agent that handles the full prospecting-to-meeting pipeline is trying to operate at autonomy layer three without the specialized agents, validation loops, or context architecture that layer three requires. The results look impressive in demos. They look different in production, where edge cases are not curated and prospects do not behave like the training data suggested they would.
The SaaS bypass is already happening

Some tools become modules, not destinations.
For each tool in your revenue stack, there are four questions worth asking now, not in eighteen months when renewal comes up.
First: does this tool have an API? If yes, an agent can use it without the UI. If no, the tool’s position is safe for now. Most revenue tools have APIs.
Second: what percentage of your team’s usage depends on the interface itself? If the answer is below 20%, an agent can replace that usage today. If it is above 60%, the interface is still delivering value through visualization, configuration, or workflow design that agents cannot yet replicate.
Third: can an agent compose this tool’s API with other tools in your stack? If yes, the tool becomes a module in a larger automated pipeline. Its value shifts from “application your team uses” to “API endpoint your agents call.” That is a very different pricing conversation.
Fourth: could you build a custom version of this tool’s core functionality with agents in a week? If yes, you are paying for convenience, not genuine complexity. That is fine as long as the convenience is worth the price. But the price of that convenience is dropping every quarter as agents get better at building things.
The disruption sequence is playing out in three phases. Right now, AI sits as a copilot on top of existing tools. This feels safe to vendors because their product is still the center of the workflow. In the next twelve to eighteen months, agents will operate the tools autonomously, using the APIs to do what humans currently do in the interfaces. Vendors will feel pressure but still own the data and the integrations. In two to three years, agents will bypass the interface layer entirely, composing raw APIs into custom pipelines that are tuned to each company’s specific workflow. The UI moat evaporates for any tool whose value was primarily making an API accessible to humans.
This does not mean every SaaS tool is doomed. Tools that manage genuine complexity (payment processing, identity management, compliance, infrastructure) earn their subscription regardless of interfaces. The audit identifies which tools are charging you for a UI wrapper on functionality that agents do not need wrapped.
The adoption chasm between builders and performers
The most consequential divide in GTM right now is not between companies that use AI and companies that do not. Nearly everyone uses AI for something. The divide is between organizations that are building agent infrastructure and organizations that are performing AI adoption.
Building looks like: a RevOps team that spent three months developing context architectures for their outbound agents, with validation loops that catch bad data before it reaches a prospect, and feedback mechanisms that improve targeting based on actual conversion data. They cannot point to a single dramatic before-and-after metric because the improvement is systemic and compounding. Their agents get better every week because the context they operate in gets richer every week.
Performing looks like: an executive who approved a six-figure contract for an “AI-powered” platform, tracked adoption by counting login rates, declared victory when 40% of the team logged in during the first month, and moved on to the next initiative. Six months later, eight people use it regularly. The ROI calculation in the board deck was generated by multiplying total employees by a vendor-supplied productivity estimate.
The gap between these two approaches compounds monthly. The teams building agent infrastructure develop institutional knowledge about what works in their specific market, with their specific ICP, for their specific product. That knowledge gets encoded into context architectures that make every subsequent agent interaction more effective. The teams performing adoption develop nothing that compounds. Every quarter looks roughly like the last one, with a different vendor name in the budget line.
The gap here has nothing to do with technology. The tools are available to both groups. It comes down to skills and orientation. The building teams treat AI agents as infrastructure that requires engineering. The performing teams treat AI agents as products that require procurement. These are fundamentally different approaches, and they produce fundamentally different outcomes over time.
What actually works today versus what will work tomorrow
The honest assessment of where agent-driven GTM stands right now: augmentation works reliably. Orchestration works for teams willing to invest in context engineering and validation infrastructure. Autonomous operation is mostly aspirational for revenue-essential workflows.
What works today: agents that draft and personalize outreach at scale, with human review before sending. Agents that enrich and score leads across multiple data sources, flagging the highest-priority accounts for human attention. Agents that monitor competitor activity, industry news, and trigger events, then surface relevant signals to the right rep at the right time. Agents that analyze pipeline data and identify patterns that humans miss. All of these operate at layer one or layer two. All of them require human judgment at the decision point. All of them produce measurable impact.
What will work over the next twelve to eighteen months: multi-agent architectures where specialized agents handle distinct phases of the revenue workflow, coordinated through explicit handoff protocols. Context architectures that encode institutional knowledge so deeply that new agents can be added to the system and immediately operate at a high level. Validation loops sophisticated enough to catch not just errors but strategic misalignment, where the agent did what it was told but what it was told was wrong.
What will work in two to three years: agents that manage entire revenue motions with minimal human oversight, not because the agents got dramatically smarter, but because the context architectures, validation systems, and feedback loops matured to the point where the margin of error is acceptably small. The agents of 2028 will not be fundamentally different from the agents of 2026. The infrastructure surrounding them will be.
The teams that win this transition will be the ones who started building the context layer and the validation layer now, when the technology is imperfect and the competitive pressure is still low. Waiting for the tools to mature before investing in the infrastructure is like waiting for cars to be reliable before building roads. The infrastructure is what makes the technology reliable. And the organizations building that infrastructure today are creating a compounding advantage that will be very difficult to replicate by the time everyone else realizes it matters.
Enjoying this essay?
Written by

Elom
GTM, growth, and revenue systems operator with 12 years across Fortune 500s, fintech, and B2B startups. Building at the intersection of AI, data, demand, and revenue.
Get the next deep-dive in your inbox
Essays on demand creation, GTM, growth engineering, and revenue systems. Free.