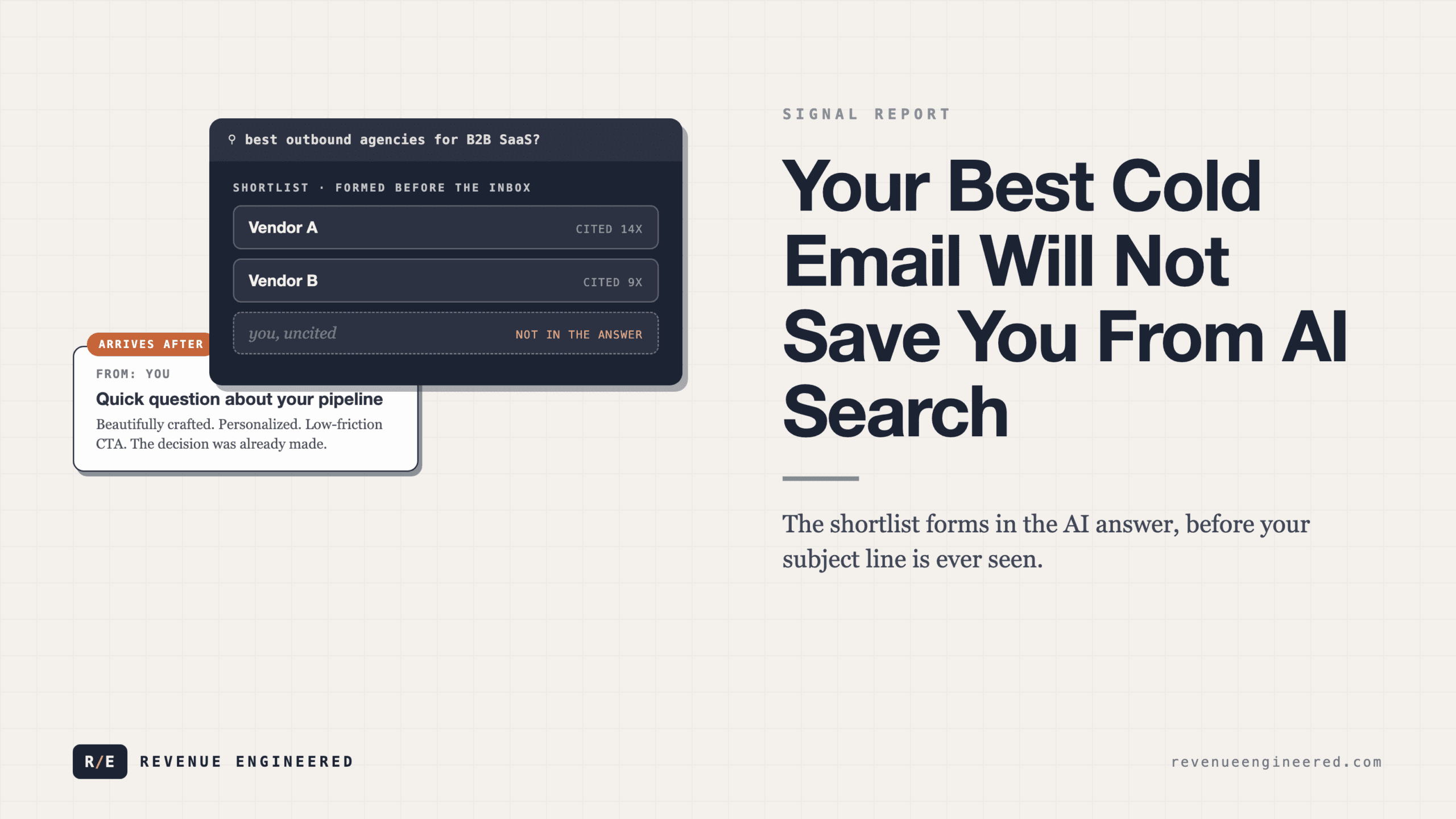
Your FAQ Page Is Your New Homepage for AI Search
LLMs pull answers from structured, question-formatted content. Your FAQ page, if built correctly, becomes the single most important page for AI search visibility. Most companies treat it as an afterthought.
Your FAQ Page Is Your New Homepage for AI Search
Most companies treat their FAQ page like a junk drawer. It sits at the bottom of the sitemap, populated with generic questions nobody asked, formatted in a collapsible accordion widget that gets updated once a quarter if at all.
That era is ending.
The rise of AI search, specifically large language models like ChatGPT, Perplexity, and Claude as primary research interfaces, has turned structured question-and-answer content into the single highest-leverage page type for organic visibility. Not blog posts. Not landing pages. Your FAQ page.
One GTM agency recently reported $506K in contract value over four months from LLM-optimized content, with LLM referral traffic growing 7.6x during that period. The specific content types driving those results were not long-form thought leadership pieces or viral social posts. They were structured, question-formatted pages that mapped directly to how language models retrieve and cite information.
I think this is one of the most underappreciated shifts in digital marketing right now. Companies are spending six figures on SEO content programs while their FAQ page sits there doing nothing for AI search. The opportunity cost is enormous, and it is almost entirely self-inflicted.
How LLMs Select Sources (And Why It Matters for Your FAQ)
To understand why FAQ pages matter for generative engine optimization, you need to understand how large language models decide which sources to cite, summarize, or surface in their responses.
LLMs do not rank pages the way Google does. They do not use PageRank. They do not count backlinks in the traditional sense. Instead, when a language model generates a response to a user query, it draws on patterns learned during training and, in the case of retrieval-augmented systems like Perplexity and ChatGPT with browsing, actively fetches and evaluates web content in real time.
The selection criteria cluster around three dimensions.
Authority signals. LLMs weight content from domains with established topical authority. If your site consistently publishes expert-level content about a specific domain and other authoritative sources reference you, language models learn to trust your domain as a reliable source. This is not the same as domain authority in the SEO sense. It is more akin to entity reputation across the training corpus.
Structured answers. When a model needs to answer a specific question, it preferentially surfaces content that is already formatted as a direct answer to that question. A paragraph buried in a 3,000-word blog post might contain the answer, but a cleanly structured Q&A pair with the question as a heading and a concise, factual answer directly below it is significantly easier for the model to identify, extract, and cite. LLMs optimize for extraction efficiency. The easier you make it, the more likely you get cited.
Entity clarity. Models need to understand what your company does, who it serves, and what makes it different. Pages that clearly define these entities, using consistent terminology, specific service descriptions, and unambiguous company information, give models the semantic scaffolding they need to recommend you in context. Vague copy like “we help businesses grow” gives the model nothing to work with.
Your FAQ page, when built correctly, hits all three dimensions simultaneously. It establishes topical authority through depth and specificity. It provides structured answers in the exact format models prefer. And it clarifies your entities through precise, question-driven definitions of who you are and what you do.

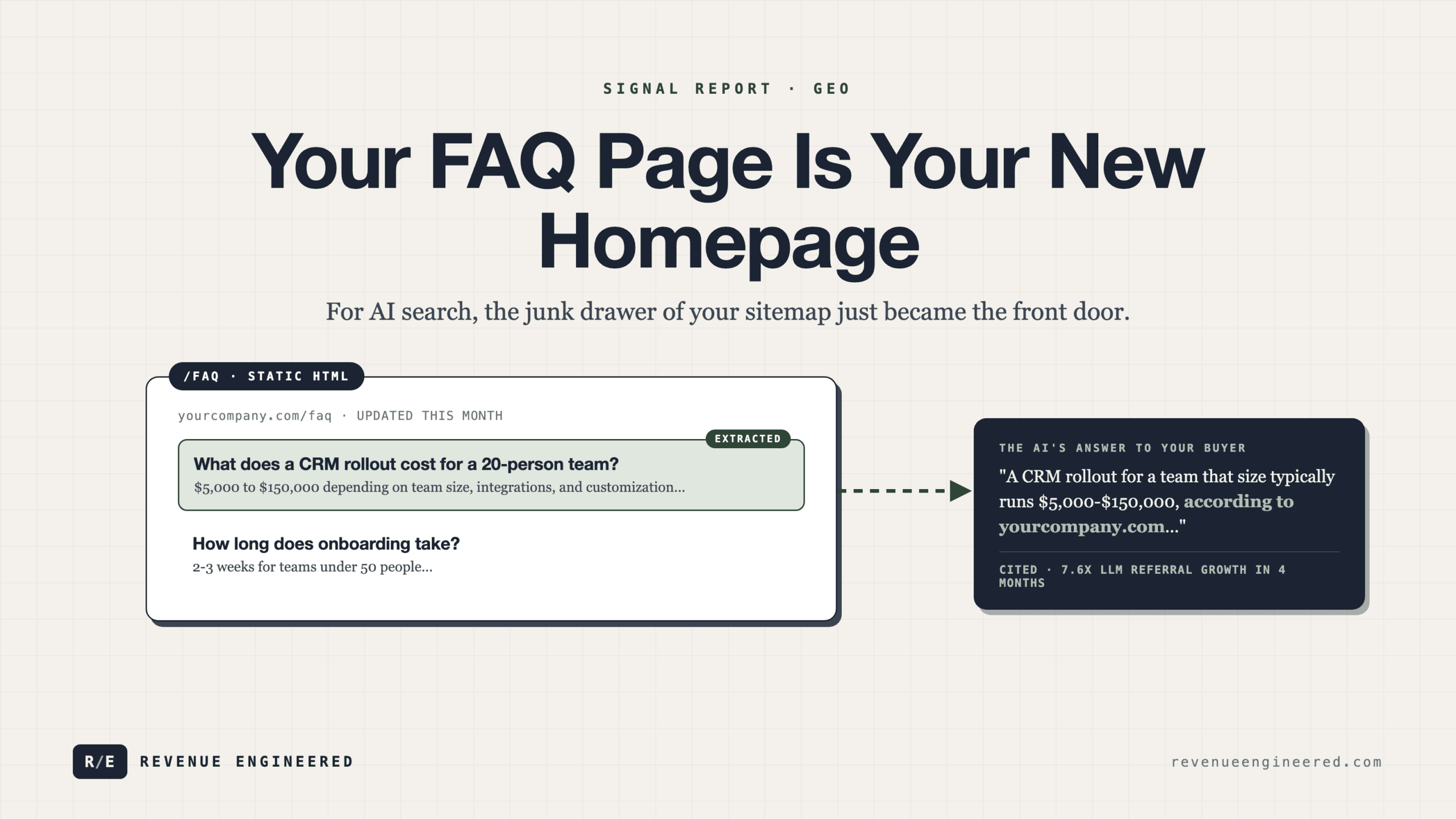
How a FAQ becomes an AI citation asset.
What Makes a FAQ “Citation-Worthy” vs. Invisible
Not all FAQ pages are created equal. Most are invisible to LLMs because they violate the structural requirements that make content extractable.
Here is what separates citation-worthy FAQs from the ones that get ignored.
Citation-worthy FAQs use real questions as headings. The question itself is an H2 or H3 element, not hidden behind a JavaScript toggle. The answer follows immediately in the next paragraph. LLMs and their retrieval systems parse HTML structure. If your question text is trapped inside a data-toggle attribute or rendered dynamically via JavaScript, it may never get indexed by the model’s retrieval layer at all.
Citation-worthy FAQs answer the exact question in the first sentence. The opening sentence of each answer should be a direct, complete response to the question. Think of it like a featured snippet on steroids. If someone asks “What is the average cost of implementing a CRM?” your first sentence should be something like “The average cost of implementing a CRM ranges from $5,000 to $150,000 depending on team size, integrations, and customization requirements.” Then expand with context, nuance, and your expertise.
Citation-worthy FAQs include specific numbers, timeframes, and concrete details. Models prefer answers that contain verifiable specifics over vague generalizations. “Our onboarding takes 2-3 weeks for teams under 50 people” is infinitely more citable than “We offer fast onboarding.” The specificity signals expertise to the model.
Citation-worthy FAQs use consistent entity naming. Every answer should use your company name, your product names, and your service names consistently and precisely. If you call your product “RevOps Automation Platform” on the homepage and “our tool” on the FAQ page, you are fragmenting the entity signal the model needs to connect your content to your brand.
Citation-worthy FAQs are comprehensive within their scope. A FAQ page with 8 generic questions is not a GEO asset. A FAQ page with 40-60 deeply specific questions covering your service categories, your process, your pricing structure, your ideal customer profile, and your differentiation is a dense node of citable content. Depth within a single domain is more valuable than breadth across many.
Invisible FAQs hide behind accordions and JavaScript rendering. If the answer text is not in the raw HTML when the page loads, many retrieval systems will not see it. This includes most collapsible FAQ widgets built with popular CMS plugins.
Invisible FAQs use questions nobody actually asks. “Why choose us?” and “What makes us different?” are vanity questions. LLM users ask questions like “What tools do I need for outbound email in 2026?” or “How do I build a GTM stack for a 10-person sales team?” Your FAQ questions need to match the actual queries people type into ChatGPT, not the questions your marketing team wishes people would ask.
The Difference Between SEO-Optimized FAQs and GEO-Optimized FAQs
I want to be precise about this because the distinction matters.
SEO-optimized FAQs are designed to rank in traditional search results. They target long-tail keywords, use structured data markup (FAQ schema), and aim for featured snippet positions on Google. This is a well-understood playbook that has worked for years.
GEO-optimized FAQs share some of those traits but optimize for a fundamentally different retrieval mechanism. Here are the key differences.
Answer completeness. SEO FAQs often give partial answers to encourage click-through. GEO FAQs give complete, self-contained answers because the LLM will extract and present the answer directly. If your answer is incomplete, the model will find a competitor’s complete answer and cite that instead.
Question formatting. SEO FAQs optimize questions for keyword density. GEO FAQs optimize questions for natural language query matching. People type questions into ChatGPT differently than they type keywords into Google. “What’s the best CRM for a 20-person B2B SaaS company?” is a GEO question. “Best CRM B2B SaaS” is an SEO keyword.
Depth per answer. SEO FAQs tend toward brevity because Google rewards concise featured snippets. GEO FAQs benefit from 150-300 word answers per question because language models have the context window to process longer responses and prefer answers that demonstrate expertise through detail.
Internal linking. SEO FAQs link to other pages on your site to distribute link equity and encourage deeper browsing. GEO FAQs still benefit from internal links, but the primary value is semantic. Each link tells the model “this topic connects to this other piece of our content,” building a richer entity graph around your brand.
Schema markup. SEO FAQs heavily rely on FAQ schema (structured data) for rich results. GEO FAQs benefit from schema but are not dependent on it. The HTML structure itself is the signal that matters most for LLM retrieval. Schema is a bonus, not the foundation.
Update frequency. SEO FAQs can sit unchanged for months. GEO FAQs need regular updates because language models, especially retrieval-augmented ones, weight freshness. If your FAQ was last updated in 2024 and a competitor’s was updated last month, the model is more likely to cite the fresher source.
The bottom line: a good SEO FAQ might be a bad GEO FAQ. The two strategies are not interchangeable.

SEO FAQ vs GEO FAQ.
A Practical Framework for Rebuilding Your FAQ as a GEO Engine
If you are serious about AI search visibility, here is how I would rebuild a FAQ page from scratch as a GEO asset. I have organized this into four phases.

The GEO FAQ rebuild workflow.
Phase 1: Query Mining
Before writing a single question, you need to understand what your target audience is actually asking language models. This is not traditional keyword research. It is conversational intent mapping.
Start by identifying the 5-10 core topics your business addresses. For a B2B SaaS company selling a sales automation platform, those topics might include outbound email, lead scoring, CRM integration, sales automation ROI, team onboarding, data enrichment, compliance, and pricing.
For each topic, generate 8-12 natural language questions that a buyer might ask a language model. Use these patterns:
- “What is the best [solution] for [specific situation]?”
- “How much does [solution] cost for [company size]?”
- “What’s the difference between [approach A] and [approach B]?”
- “How do I [specific task] without [common pain point]?”
- “What do I need to know before [buying/implementing/switching]?”
- “How long does it take to [achieve specific outcome]?”
Test these questions in ChatGPT, Perplexity, and Claude. Look at what sources they cite. Look at the format of the answers they give. Reverse-engineer the content structure that gets cited.
This process typically yields 50-80 questions across all your topic clusters.
Phase 2: Answer Architecture
Each answer needs to follow a specific structure for maximum citability.
First sentence: direct answer. Answer the question completely in one sentence. This is the sentence the LLM will most likely extract as the core of its response.
Second paragraph: context and specifics. Expand with numbers, timeframes, use cases, or conditions that affect the answer. This is where you demonstrate expertise and provide the nuance that makes your answer more valuable than a generic response.
Third paragraph: your company’s perspective or approach. Naturally weave in how your company handles this specific question. Not a sales pitch. A practitioner’s answer that happens to reference your approach. “At [Company Name], we typically see enterprise teams complete this process in 3-4 weeks because our onboarding includes dedicated implementation support.”
Final sentence: connector. Link to a related question or deeper resource on your site. “For a breakdown of how this integrates with your existing CRM, see our answer on CRM migration timelines below.”
Each answer should run 150-300 words. Shorter than that and you lack the depth for citation. Longer and you risk diluting the core answer.
Phase 3: Page Structure and Technical Implementation
The page itself needs to be built for extraction.
Use static HTML. No JavaScript-rendered accordions, no dynamic content loading, no “click to expand” widgets. Every question and answer must be present in the raw HTML when the page loads. Server-side rendered or static site generation. This is non-negotiable.
Use semantic headings. Each question should be an H2 or H3 element. The answer should follow in standard paragraph tags. This heading structure gives retrieval systems a clear signal about content hierarchy.
Add FAQ schema markup. Yes, even though schema is not the primary driver for GEO, it helps. Use JSON-LD format with FAQPage and Question/Answer pairs. This also gives you the traditional Google rich results as a bonus.
Organize by topic cluster. Group related questions under topic-level H2 headings. This creates clear semantic sections that help models understand the topical structure of your content. A flat list of 60 unrelated questions is harder for models to navigate than 6 clusters of 10 related questions.
Keep the URL clean and permanent. Your FAQ page URL should be something like /faq or /answers or /frequently-asked-questions. Not /resources/help/faq-v3-updated. Stability in URL structure builds authority over time.
Add a last-updated date. Visible on the page, ideally in a machine-readable format. This signals freshness to retrieval systems.
Phase 4: Ongoing Maintenance
A GEO-optimized FAQ is not a build-once asset. It is a living document.
Monthly question audit. Every month, check what new questions your audience is asking by monitoring ChatGPT, Perplexity, and search console query data. Add new questions. Update existing answers with fresher data.
Quarterly depth expansion. Each quarter, select the 5-10 highest-value questions and expand their answers with new data, case studies, or updated statistics. Deeper answers tend to get cited more over time.
Competitive monitoring. Track which competitors are getting cited in LLM responses for your target queries. Read their cited content. Write better, more specific, more authoritative answers.
Freshness signals. Update the page timestamp whenever you make substantive changes. Even small updates signal to retrieval-augmented models that your content is current.
The Math That Makes This Worth Your Time
Consider the numbers. One agency tracked a 7.6x increase in LLM referral traffic over four months after investing in structured, question-formatted content. They attributed $506K in contract value to this channel in the same period.
Now think about the effort required. A well-built GEO FAQ page takes 2-3 days of focused work to create. The ongoing maintenance is 2-4 hours per month. Compare that to a traditional SEO content program that requires weekly blog posts, link building, technical audits, and content refreshes.
The ROI per hour of effort is not even close. A single, well-structured FAQ page can outperform an entire blog with 50 posts in LLM citation frequency, simply because the FAQ is formatted for extraction while the blog posts are formatted for browsing.
I am not saying kill your blog. I am saying that if you are investing 40 hours per month in content and zero of those hours go toward your FAQ page, you are leaving the highest-leverage GEO asset on the table.
What I See Companies Getting Wrong Right Now
The most common mistake is treating GEO as a layer on top of existing SEO. Companies add FAQ schema to their current FAQ page, call it “GEO-optimized,” and wait for results.
That does not work. If your FAQ page has 12 generic questions with two-sentence answers behind JavaScript accordions, adding schema markup changes nothing for LLM visibility. You are optimizing an empty container.
The second mistake is over-indexing on the FAQ page format itself and ignoring the content quality. A FAQ page with 60 questions full of vague, marketing-speak answers is still invisible. “We provide industry-leading solutions for modern businesses” will never get cited by a language model because it contains zero extractable information.
The third mistake is building the FAQ and then never updating it. LLMs are increasingly retrieval-augmented, meaning they fetch live web content. A FAQ page that has not been updated in six months will lose ground to competitors who update monthly. Freshness is a compounding advantage.
My Take: The Window Is Open, But It Will Not Stay Open Forever
I believe the companies that rebuild their FAQ architecture in the next 6-12 months will own the AI search channel for the next 2-3 years. Here is why.
LLMs are still forming their understanding of which sources to trust for which topics. The models are learning, right now, which domains provide reliable, structured, specific answers to industry questions. The entities and brands that establish themselves as authoritative sources during this formative period will have a compounding advantage as these models continue to train and refine their source preferences.
This is analogous to the early SEO era when companies that invested in search visibility between 2005 and 2010 built moats that lasted a decade. The companies that waited until 2015 found the cost of competing had increased by an order of magnitude.
The AI search version of this land grab is happening right now. And the FAQ page, boring as it sounds, is the most efficient piece of real estate you can claim.
I am not suggesting you abandon your other channels. Outbound, paid, content, SEO, all of these still matter. But if you are allocating zero resources to your FAQ page as a GEO asset, you are ignoring the channel that has the best effort-to-visibility ratio in the current environment.
The question is not whether AI search will become a major buyer research channel. That has already happened. The question is whether you will be the answer when your buyers ask.
Build your FAQ page like your revenue depends on it. Because increasingly, it does.
Enjoying this essay?
Written by

Elom
GTM, growth, and revenue systems operator with 12 years across Fortune 500s, fintech, and B2B startups. Building at the intersection of AI, data, demand, and revenue.
Get the next deep-dive in your inbox
Essays on demand creation, GTM, growth engineering, and revenue systems. Free.