The PMF Treadmill: Why AI Companies Can Never Stop Sprinting
Product-market fit used to be a destination. In AI, it’s a moving target.
For the better part of two decades, the SaaS growth playbook had a comforting narrative arc. You spent your early months searching for product-market fit. You ran experiments, talked to customers, iterated on positioning. And then, if you were one of the lucky ones, you found it. PMF was a destination. You arrived, planted a flag, and started scaling. The next five to seven years were about building on that foundation: layering on features, expanding into adjacent segments, and compounding retention into durable revenue.
That story made sense when the competitive clock moved in 18-month cycles. A feature took six months to build, another six to bring to market, and a competitor needed roughly the same timeline to replicate it. The window of advantage was measured in years, and the moat was built from accumulated product depth, customer workflows, and switching costs. If you had strong gross retention (north of 90%) and healthy expansion revenue, your PMF was a load-bearing wall you could build a company on top of.
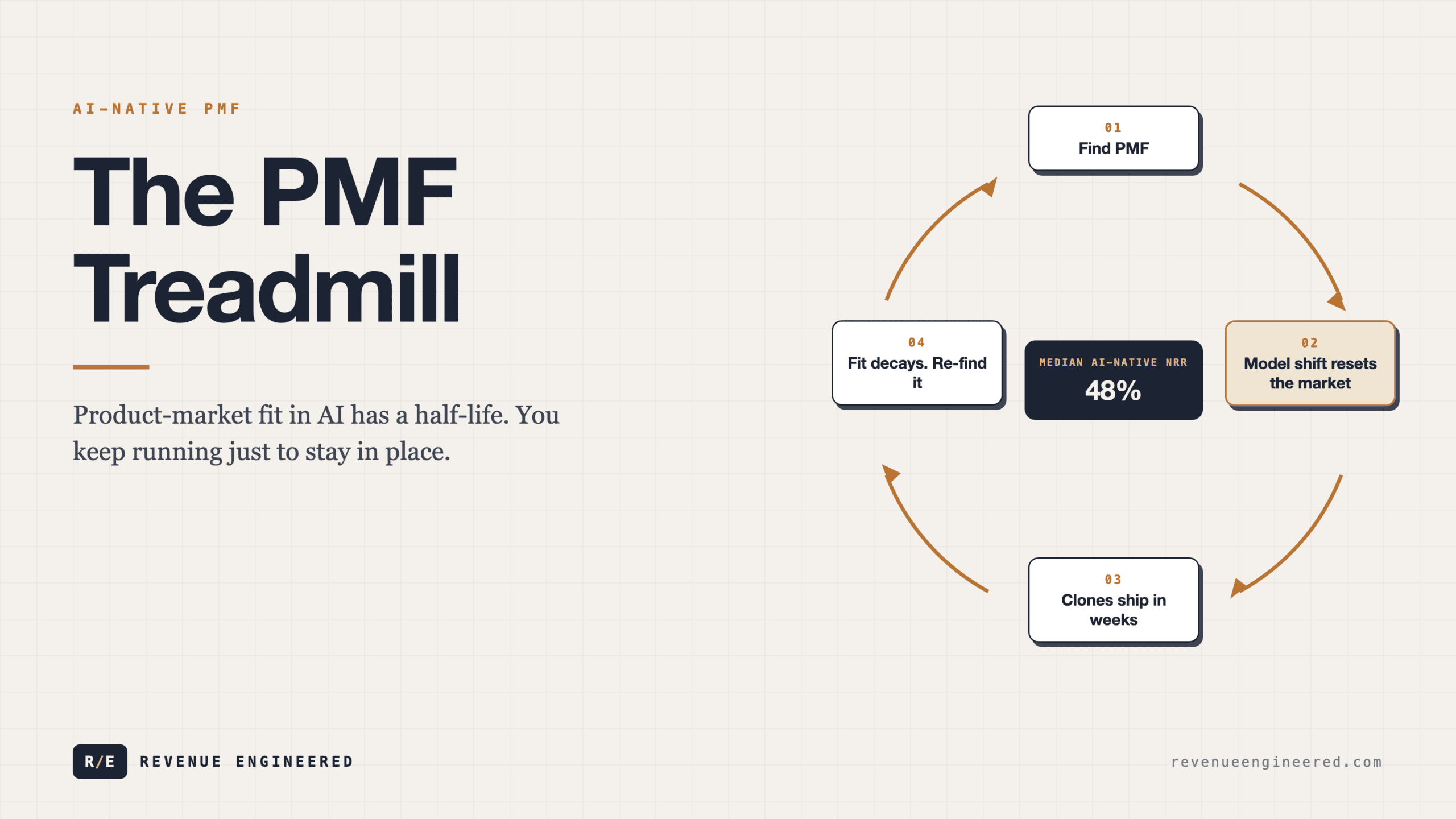
AI has broken that clock. The companies building on foundation models are discovering that product-market fit is no longer a milestone. It is a treadmill. You have to keep running just to stay in the same place, because the ground beneath your product shifts every time a new model drops, every time a competitor ships a clone in weeks instead of months, and every time customer expectations reset upward. The structural dynamics that made SaaS PMF durable are precisely the ones that make AI PMF fragile.
The speed of competitive response has collapsed

speed of competitive response has collapsed reframed as system design.
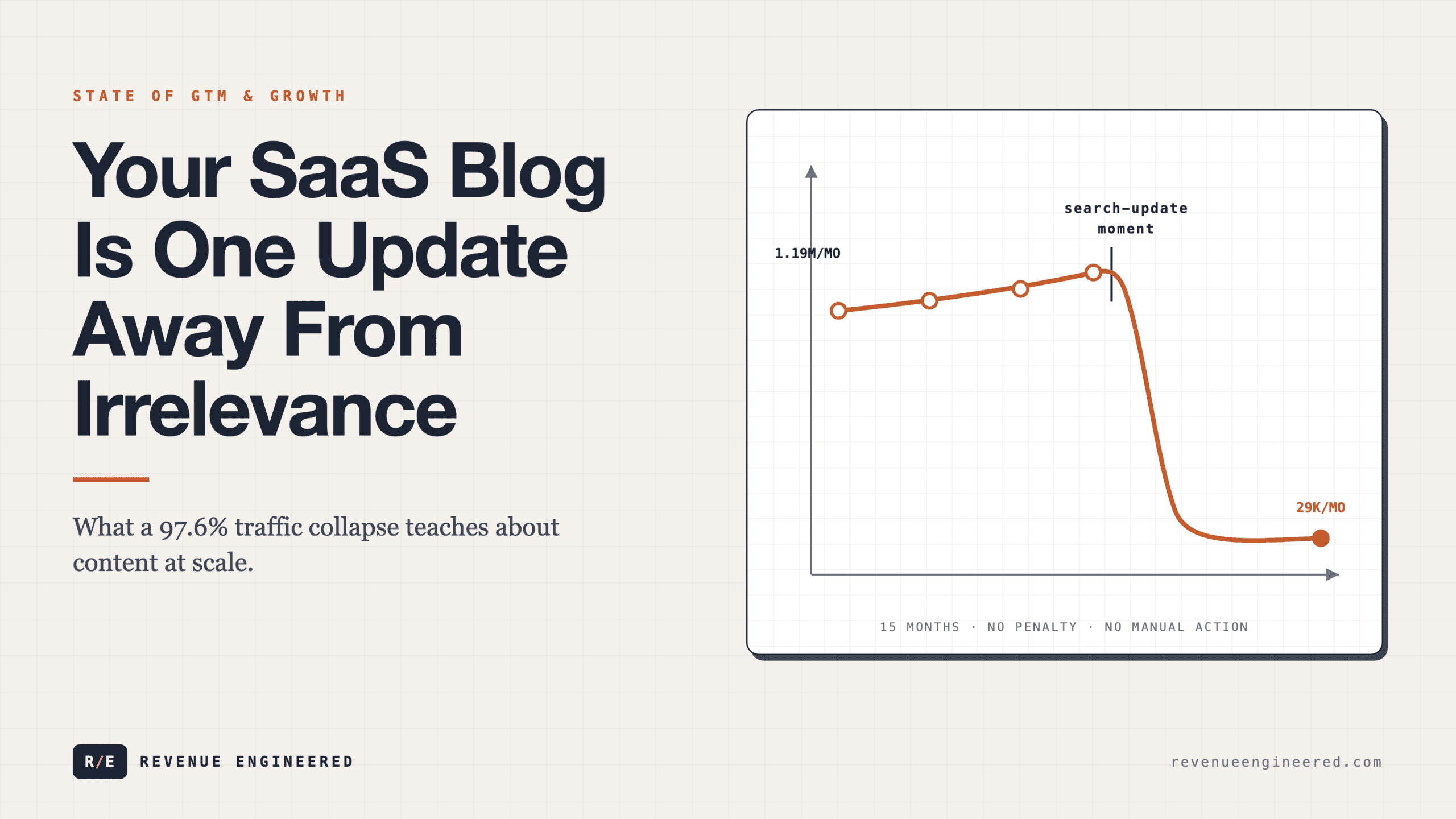
Consider the timeline compression. In traditional SaaS, the median time for a competitor to replicate a core feature was 12 to 18 months. That included recruiting, building, testing, and distributing. The data from AI-native companies tells a different story. State-of-the-art models stay roughly six months ahead of their open-source alternatives. New entrants regularly produce near-peer capabilities through model distillation, and the app layer above those models can be rebuilt in weeks. What used to require a full engineering team and multiple quarters now requires a weekend hackathon and an API key.
This changes the competitive calculus at a fundamental level. In the old world, shipping first created a durable advantage because the cost of replication was high. In the AI world, shipping first creates a temporary advantage because the cost of replication has collapsed to near zero. The ecosystem is full of startups showing zero to $5M+ ARR growth in under a year, and in most cases, these companies do not even specify which underlying model they use. The model is interchangeable. The interface is copyable. The only question left is: what do you actually own?
The thin wrapper problem
This is where the “GPT wrapper” critique lands hardest. If your product is a user interface sitting on top of a foundation model, your defensibility is exactly as thick as that interface. Which, in most cases, is very thin.
The prior theory of AI defensibility assumed that building successive generations of models would require exponentially more capital, creating a scale-effect moat. A handful of large model companies would create all the value and tax the ecosystem of applications above them. That theory has run into serious complications. Open-source alternatives consistently close the gap. Model distillation lets smaller players achieve comparable performance at a fraction of the cost. And the gap between the frontier model and the next-best option keeps narrowing.
So the application layer has become the real battleground. But here is the uncomfortable truth: most AI applications have not yet built anything that a new model release could not make irrelevant. If GPT-4 was the foundation your product rested on, and GPT-5 can do what your product does natively, you do not have a product anymore. You had a timing advantage that has expired. The history of computing platforms shows this pattern clearly. In the early days of web apps, the first generation of startups succeeded simply because they worked, because building anything on the internet was hard enough that “it functions” was the feature. Two decades later, building a web app became trivial, and the products that won were the ones with network effects, distribution advantages, and deep workflow integration, not the best technology.
AI is speedrunning that same transition. The entire arc from “expensive and rare” to “cheap and commoditized” that took web apps 20 years is compressing into three to five.
Where retention breaks down
The retention data on AI-native companies is sobering. We’re seeing research across thousands of software companies that breaks out AI-native companies from traditional B2B and B2C SaaS. The numbers tell a clear story.
B2B SaaS companies show median net revenue retention of about 82%. B2C SaaS sits around 49%. AI-native companies come in even below B2C, with median gross retention around 40% and median NRR of 48%. Read that again: the median AI-native company loses 60% of its revenue base annually.
The price tier data makes this worse. AI products selling below $50 per month see gross retention of just 23% and NRR of 32%. That is 20 percentage points below either B2B or B2C SaaS at the same price point. At higher price tiers (above $250 per month), AI retention starts to resemble traditional B2B SaaS, with GRR around 70% and NRR around 85%. But most AI companies are not operating at those price points yet.
There is some positive trend. Median AI GRR improved from 27% in January 2025 to 40% by September. The early tourists are leaving, and the remaining users appear more committed. But even at 40%, you are replacing more than half your customer base every year. That is a business running on a treadmill, not building on a foundation.
The retention math creates a specific growth trap. Early-stage AI startups can grow fast (200%+ year-over-year) even with NRR below 40%. The sheer novelty of the product, combined with low-friction acquisition, masks the retention problem. But as the install base grows, churn scales with it. You need exponentially more new customers just to maintain the same revenue, let alone grow. Companies with low retention that reach scale are three times more likely to be shrinking than growing quickly.
The “AI tourist” phenomenon
Part of the retention problem is structural to how AI products monetize. Traditional SaaS companies used freemium or reverse trial models. Users had plenty of time to explore before paying, and when they did pay, they had already made a conscious buying decision. Gross margins above 80% made it cheap to support free users.
AI flips those economics. Every token has a cost. Products push for conversion either immediately or upon any meaningful usage. Some impose daily usage caps that force upgrades before users have had time to evaluate whether the product fits their workflow. The result: people start paying because they are intrigued by the possibility of what the product could do, not because they have validated how it fits their business. They are AI tourists, not committed buyers.
The data backs this up. Contracts with three-month opt-out clauses are seeing 70-80% opt-out rates. Revenue that companies call “ARR” is frequently experimental spend, usage-based consumption that fluctuates wildly, or professional services from forward-deployed engineers. It is not the high-margin, predictable, growing revenue that the SaaS valuation framework was designed for.
It is hard to call a business recurring when 60% of the install base walks out the door each year.
Who has built durable PMF in AI

Who has built durable PMF in AI as a maturity path.
Not everyone is on the treadmill. The companies that have built durable product-market fit in AI share common structural characteristics, and none of them are about having a better model.
The first group owns the data layer. These companies have accumulated proprietary datasets through their product usage that improve the product in ways competitors cannot replicate by spinning up a new API integration. The data compounds. Each customer interaction makes the product better for the next customer, and that flywheel cannot be bootstrapped from scratch.
The second group owns the workflow. They have embedded themselves so deeply into how teams actually work that ripping them out would require restructuring business processes. This is the same moat that made Salesforce durable despite a decade of “Salesforce killers.” When your product becomes the system of record, when people build their operating rhythms around it, switching costs are real even if the technology underneath is commoditized.
The third group owns distribution. They have built network effects, viral loops, or brand positioning that creates a structural acquisition advantage. In a world where copying the product takes weeks, the question becomes whether you can acquire and retain users faster than your clones can. Products that generate shareable outputs, that grow through team collaboration, that build communities around usage patterns have a distribution moat that pure technology cannot replicate.
The companies that are doing well tend to combine at least two of these. They own data and workflow. Or they own workflow and distribution. Pure technology plays, the ones betting that their model or their UI will remain superior, are the ones most exposed to the treadmill dynamic.
What this means for growth teams
Building a growth engine on shifting ground requires a fundamentally different operating model than what most revenue teams are used to.
The first shift is from optimizing to experimenting at much higher velocity. Traditional growth teams spent 80% of their time on optimization, running A/B tests on onboarding flows, tweaking pricing pages, improving activation metrics. That approach assumes a stable product-market fit that you can incrementally improve. When PMF is moving, optimization is polishing a surface that might not exist next quarter. The teams that are succeeding spend the majority of their time on bigger bets, testing entirely new use cases, new segments, new positioning. The ratio of exploration to exploitation has to flip.
The second shift is around activation metrics. In traditional SaaS, activation was defined around setup actions (uploading data, configuring integrations, inviting team members). In AI products, the “aha” moment happens on the first prompt. Time-to-value has collapsed to seconds. That sounds like a good thing, but it creates a trap: users activate instantly but do not retain because the initial dopamine hit is not the same as a sustained workflow change. The growth teams that are solving this problem are redefining activation around value delivery, not value demonstration. The metric is not “user generated their first output” but “user deployed that output into a real workflow.”
The third shift is in monetization architecture. Credit-based and usage-based models are becoming the default because per-seat pricing does not map to AI cost structures (one user might consume 10x the compute of another). But usage-based pricing creates its own retention risk. When there is no annual contract, no switching cost baked into the billing model itself, every month is a renewal decision. The teams navigating this well are blending credits with subscription tiers, offering annual plans that give customers more time to embed the product (the data shows NRR is 10 to 20 percentage points higher on annual plans versus monthly), and deliberately narrowing the gap between when the product is purchased and when it is actually adopted into daily operations.
The compounding problem

compounding problem translated into operating choices.
There is a deeper issue that most people in the AI space have not yet confronted: the treadmill is accelerating. Each new foundation model release does not just improve capabilities linearly. It resets customer expectations, opens new competitive surface area, and collapses the time between “breakthrough feature” and “table stakes.” The interval between model generations is getting shorter. The number of teams capable of building competitive applications is growing. And the cost of switching between AI products is, in most cases, negligible.
For traditional SaaS, the compounding worked in the company’s favor. Each year of retention data, each integration built, each workflow embedded made the business more durable. For AI companies, the compounding works in the opposite direction. Each new model makes last quarter’s differentiation less meaningful. Each new competitor makes the market more crowded. Each price reduction in the model layer squeezes margins further.
The companies that will win are the ones building assets that compound in the right direction: proprietary data that gets better with use, workflow integrations that deepen over time, and distribution advantages that grow faster than the competitive set. Everything else is a feature that will be commoditized.
Where this is heading
The AI industry is about to learn a lesson that the last generation of SaaS companies learned the hard way, but faster. Revenue growth without retention is a sugar high. The companies racing to $100M ARR in under a year will face a reckoning when the growth rate cannot outrun the churn rate, and for most of them, that crossover point is closer than their pitch decks suggest.
The teams that will build durable businesses are the ones treating PMF as a process, not a milestone. They are instrumenting retention by cohort, by use case, by price tier. They are separating tourist revenue from committed revenue. They are building moats in the data layer and the workflow layer, not the model layer. And they are honest about a basic mathematical reality: when you lose 60% of your customers every year, you need to find a way to either fix the leak or make the bucket a lot bigger, and making the bucket bigger eventually stops working.
Product-market fit in AI is real. But it has a half-life. The question for every AI company is whether they can build something durable before their current fit decays, and whether they can keep doing that, quarter after quarter, without falling off the treadmill. My bet is on the teams that own the workflow and the data, not the model. The model is the commodity. The workflow is the moat. And the teams that understand that distinction early will be the ones still standing when the treadmill finally slows down.
Enjoying this essay?
Written by

Elom
GTM, growth, and revenue systems operator with 12 years across Fortune 500s, fintech, and B2B startups. Building at the intersection of AI, data, demand, and revenue.
Get the next deep-dive in your inbox
Essays on demand creation, GTM, growth engineering, and revenue systems. Free.